非同期型FD「 小規模大学における数理・データサイエンス・AI教育プログラム(リテラシーレベル)の導入と DX――東日本国際大学の事例共有 」
全大学生が基礎レベルの数理・データサイエンス・AIの知識・技能を身に付けられるようになることを目的とした数理・データサイエンス・AI教育プログラムをどのように実装していくかは、特に有する学部・学科数が少なく、またその分野においてデータ分析が必ずしも一般的でない場合や、リソースが限定された小規模大学において難しい課題となっています。
他方で、リテラシーレベルにおいては、現在誰もが身に付けていることが期待される教養としての側面も強く強調されており、そうした観点から整理することで、以上のような大学においてもこうしたプログラムを意味のあるかたちで実施することが可能であると思われます。
本事例共有では、テーマに合わせ、新型コロナウイルス感染拡大状況下で蓄積されたノウハウから、報告を非同期型で実施し、いただいたご質問について順次回答していきます。
以下の動画において、どのような考えで検討を進めたか等を説明しております。質問は動画下のリンクからお寄せください。
全体像
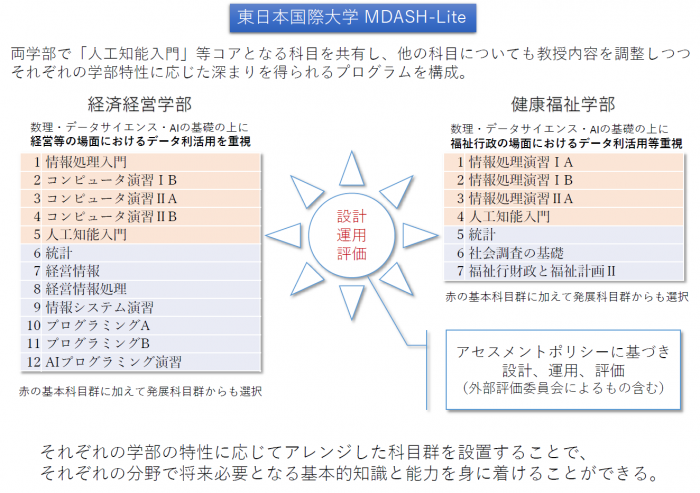
概要
本ページでは東日本国際大学における数理・データサイエンス・AI教育プログラム(リテラシーレベル)について説明します。
東日本国際大学では、AI時代の誰もが必要とする数理・データサイエンス・AIについての基礎教養を身につけることができるように、数理・データサイエンス教育強化拠点コンソーシアム作成のモデルカリキュラムに基づいた教育プログラムを全学を対象として開講しています。
特徴として、基本的な知識について両学部での共通科目を設定しつつ、 経済経営学部、健康福祉学部のそれぞれで将来必要になるであろう能力を見越して、それぞれに合わせた独自のプログラムを提供していること、アセスメントポリシーに基づいた質保証を行っていることがあげられます。
授業方法について
それぞれの学部において、学部特性に応じた学修成果を定めています。それらの学修成果に対応するかたちで、基礎的知識については、講義形式や集団での実習形式を基本としていますが、講義形式の授業においても、本学の他の授業と同様に、知識と技能を自分のものとするために、実際に自分で能動的に考え実施してみるアクティブ・ラーニング形式の要素を組み込み、学修成果の習得状況について小テストや課題提出を通じたフィードバックを行います。またデータについての踏み込んだ分析やプログラミング知識については、実際の実例に基づいた課題を用意し、それに取り組むことで実践的な能力を身に付けることを目指しています(さらに一部科目においては、地域の企業等と協力し、匿名化された実データ等での分析を行います)。
実施体制と内部質保証の体制について
本プログラムは、高等教育研究開発センターが調整を行い、本学の情報系の教員と実データ分析を行う各学部教員が構成するMDASH-Liteワーキンググループでのプログラムの検討を通じて構成されたものです。
プログラム実施の自己点検と改善のプロセスについては、本学のアセスメントポリシーに基づいて実施されます。
| 委員会等 | 役割 |
| MDASH-Liteワーキンググループ | 本プログラムを構成する学修成果と科目群の関係が適切に設定され、運用されているかを検証・評価し、改善する(高等教育研究開発センター構成員と各学科長、情報系教員と実データ分析にかかわる教員から構成される)。 |
| 高等教育研究開発センター | 学部間の調整と、プログラムの検証・評価のための素材となるIRの実施を行う。なおセンター長は、全体のコーディネートの責任を持つ。 |
| 各学部教務委員会 | 各学部に向けて調整されたプログラムが科目レベルで適切に実装・運用されているかを、シラバスチェック、成績分布等の分析を通して検証・評価し、改善する。 |
| 学部教授会 | プログラムが学部の教育課程において、学部の3つのポリシーとの関係で適切に実装・運用されているかを検証・評価し、改善する。 |
| 大学協議会 | 機関レベルにおいて、本プログラムが適切に運用されているかを検証・評価し、改善する。 |
| 自己点検・評価委員会 | 本プログラムが、中長期計画との関連で、適切に運用されているかを記録・検証し、各レベルに必要なフィードバックを行う。 |
| 外部評価委員会 | 自己点検評価が適切に機能しているか、またプログラムの実装と運営が地域の多様なステークホルダーの要請と合致しているかを検証・評価し、各レベルに必要なフィードバックを行う。 |
プログラムの目標等
各分野で必要となる内容を構成していることから、本プログラムの履修について、オリエンテーション等で案内をしています。またMoodle上で質問をしやすい環境等を構築しています。
本プログラム履修者の数値目標は以下の通りとなっています(カッコ内は収容定員に対する割合)。
令和3年度 238名 (29%)
令和4年度 420名 (52%)
令和5年度 450名 (56%)
令和6年度 475名 (59%)
令和7年度 500名 (62%)
経済経営学部の教育プログラム
以下のようにプログラムの学修成果を定めています。
全学ディプロマポリシーの2に定める要素の一つとして、現在の教養として必要となるAI等についての基本的知識を身につけ、基本的なデータについてのリテラシーを身につける。また希望する学生は、学部ディプロマポリシー1に定める要素の一つとして、さらに踏み込んだ統計やプログラミング(伝統的なAIに関連したものを含む)の基礎を習得することができる。
経済経営学部では、基本科目群(下記1~5)は5科目10単位のすべて、発展科目群(6~12)から最低1科目2単位を取得すること。(5~7は両学共通)
なお各科目の具体的なシラバスについては、オンライン・シラバスシステムで最新の情報を確認されたい。
- 情報処理入門
- コンピュータ演習ⅠB
- コンピュータ演習ⅡA
- コンピュータ演習ⅡB
- 人工知能入門
- 統計
- 経営情報
- 経営情報処理
- 情報システム演習
- プログラミングA
- プログラミングB
- AIプログラミング演習
| 領域名 | 内容 | 経済経営学部科目名(太字は基礎科目群) |
| 領域1 | 現代社会において、情報とはどのような意味を持つものか。それによって社会にどのような変化が起きているかを理解する。また、その具体例として、AIがどのような仕組みで機能し、どのような分野で活用されているかを理解する。 | 情報処理入門 人工知能入門 |
| 領域2 | 社会で活用されているデータはどのようなものであり、どう活用されているかを理解する。またコンピュータの中ではそうしたデータがどのように表現、加工されているかを理解する。 | 情報処理入門 人工知能入門 経営情報 |
| 領域3 | どのような分野において、どのようなかたちでデータの利活用が行われているか、その実際を見る。また、発展的な学習として、実際にシステム構築を行い、実地に理解する。 | 人工知能入門 経営情報 経営情報処理 |
| 領域4 | データ活用やAIにおいて問題となるセキュリティや個人の権利の保護の問題について理解する。さらに踏み込んだ内容として、ITガバナンスの全体や、今後生じる未知の状況についても理解するための下地を形成する。 | 情報処理入門 コンピュータ演習ⅡB 経営情報 |
| 領域5 | 実際にデータを扱うことで、情報に加工する際の手法や注意、読む際の注意、分析の提示(説明)の際の注意を学ぶ。 | コンピュータ演習ⅠB コンピュータ演習ⅡA コンピュータ演習ⅡB 経営情報処理 統計 |
| その他のオプションの内容・要素 | 経済経営学部授業科目名 |
| 統計及び数理基礎 | 統計 |
| アルゴリズム基礎 | プログラミングA AIプログラミング演習 |
| データ構造とプログラミング基礎 | プログラミングB |
| その他 | 情報システム演習 |
健康福祉学部の教育プログラム
以下のようにプログラムの学修成果を定めています。
全学ディプロマポリシーの2に定める要素の一つとして、現在の教養として必要となるAI等についての基本的知識を身につけ、基本的なデータについてのリテラシーを身につける。また学部ディプロマポリシー2に定める要素の一つとして、さらに踏み込んだ統計や社会福祉分野を中心としたデータの扱いを習得することができる。
健康福祉学部では、基本科目群(下記1~4)4科目5単位を取得の上、発展科目群(5~7)から最低1科目2単位を取得のこと。(5~7は両学共通)
なお各科目の具体的なシラバスについては、オンライン・シラバスシステムで最新の情報を確認されたい。
- 情報処理演習ⅠA
- 情報処理演習ⅠB
- 情報処理演習ⅡA
- 人工知能入門
- 統計
- 社会調査の基礎
- 福祉行財政と福祉計画Ⅱ
| 領域名 | 内容 | 健康福祉学部科目 |
| 領域1 | 現代社会において、情報とはどのような意味を持つものか。それによって社会にどのような変化が起きているかを理解する。 また、その具体例として、AIがどのような仕組みで機能し、どのような分野で活用されているかを理解する。 | 情報処理演習ⅠA 人工知能入門 |
| 領域2 | 社会で活用されているデータはどのようなものであり、どう活用されているかを理解する。またコンピュータの中ではそうしたデータがどのように表現、加工されているかを理解する。 | 情報処理演習ⅠA 情報処理演習ⅠB 社会調査の基礎 福祉行財政と福祉計画Ⅱ |
| 領域3 | どのような分野において、どのようなかたちでデータの利活用が行われているか、その実際を見る。また、発展的な学習として、実際にシステム構築を行い、実地に理解する。 | 人工知能入門 |
| 領域4 | データ活用やAIにおいて問題となるセキュリティや個人の権利の保護の問題について理解する。さらに踏み込んだ内容として、ITガバナンスの全体や、今後生じる未知の状況についても理解するための下地を形成する。 | 情報処理演習ⅠA 社会調査の基礎 |
| 領域5 | 実際にデータを扱うことで、情報に加工する際の手法や注意、読む際の注意、分析の提示(説明)の際の注意を学ぶ。 | 情報処理演習ⅠB 情報処理演習ⅡA 統計 社会調査の基礎 福祉行財政と福祉計画Ⅱ |
各科目で学習できる内容について(モデルカリキュラムとの対応)
上記諸領域は、以下のコンソーシアムと文部科学省が示す指針のカテゴリーに対応している。
| カテゴリ | 文部科学省様式分類名称 | コンソーシアム 「モデルカリキュラム」 大項目 | コンソーシアム 「モデルカリキュラム」小項目 | コンソーシアム 「モデルカリキュラム」 期待される学修内容 | コンソーシアム 「モデルカリキュラム」 キーワード |
| (1)A | (1)現在進行中の社会変化(第4次産業革命、Society
5.0、データ駆動型社会等)に深く寄与しているものであり、それが自らの生活と密接に結びついている ※モデルカリキュラム導入1-1、導入1-6が該当 | 1.
社会におけるデータ・AI利活用 | 1-1. 社会で起きている変化 | 社会で起きている変化を知り、数理・データサイエンス・AIを学ぶことの意義を理解する | ・ビッグデータ、IoT、AI、ロボット ・データ量の増加、計算機の処理性能の向上、AIの非連続的進化 ・第4次産業革命、Society 5.0、データ駆動型社会 ・複数技術を組み合わせたAIサービス ・人間の知的活動とAIの関係性 ・データを起点としたものの見方、人間の知的活動を起点としたものの見方 |
| (1)B | (1)現在進行中の社会変化(第4次産業革命、Society
5.0、データ駆動型社会等)に深く寄与しているものであり、それが自らの生活と密接に結びついている ※モデルカリキュラム導入1-1、導入1-6が該当 | 1.
社会におけるデータ・AI利活用 | 1-6. データ・AI利活用の最新動向 | データ・AI利活用における最新動向(ビジネスモデル、テクノロジー)を知る | ・AI等を活用した新しいビジネスモデル(シェアリングエコノミー、商品のレコメンデーションなど) ・AI最新技術の活用例(深層生成モデル、敵対的生成ネットワーク、強化学習、転移学習など) |
| (2)A | (2)「社会で活用されているデータ」や「データの活用領域」は非常に広範囲であって、日常生活や社会の課題を解決する有用なツールになり得るもの ※モデルカリキュラム導入1-2、導入1-3が該当 | 1.
社会におけるデータ・AI利活用 | 1-2. 社会で活用されているデータ | どんなデータが集められ、どう活用されているかを知る | ・調査データ、実験データ、人の行動ログデータ、機械の稼働ログデータなど ・1次データ、2次データ、データのメタ化 ・構造化データ、非構造化データ(文章、画像/動画、音声/音楽など) ・データ作成(ビッグデータとアノテーション) ・データのオープン化(オープンデータ) |
| (2)B | (2)「社会で活用されているデータ」や「データの活用領域」は非常に広範囲であって、日常生活や社会の課題を解決する有用なツールになり得るもの ※モデルカリキュラム導入1-2、導入1-3が該当 | 1.
社会におけるデータ・AI利活用 | 1-3. データ・AIの活用領域 | さまざまな領域でデータ・AIが活用されていることを知る | ・データ・AI活用領域の広がり(生産、消費、文化活動など) ・研究開発、調達、製造、物流、販売、マーケティング、サービスなど ・仮説検証、知識発見、原因究明、計画策定、判断支援、活動代替、新規生成など |
| (3)A | (3)様々なデータ利活用の現場におけるデータ利活用事例が示され、様々な適用領域(流通、製造、金融、サービス、インフラ、公共、ヘルスケア等)の知見と組み合わせることで価値を創出するもの ※モデルカリキュラム導入1-4、導入1-5が該当 | 1. 社会におけるデータ・AI利活用 | 1-4. データ・AI利活用のための技術 | データ・AIを活用するために使われている技術の概要を知る | ・データ解析:予測、グルーピング、パターン発見、最適化、シミュレーション・データ同化など ・データ可視化:複合グラフ、2軸グラフ、多次元の可視化、関係性の可視化、地図上の可視化、 挙動・軌跡の可視化、リアルタイム可視化など ・非構造化データ処理:言語処理、画像/動画処理、音声/音楽処理など ・特化型AIと汎用AI、今のAIで出来ることと出来ないこと、AIとビッグデータ ・認識技術、ルールベース、自動化技術 |
| (3)B | (3)様々なデータ利活用の現場におけるデータ利活用事例が示され、様々な適用領域(流通、製造、金融、サービス、インフラ、公共、ヘルスケア等)の知見と組み合わせることで価値を創出するもの ※モデルカリキュラム導入1-4、導入1-5が該当 | 1. 社会におけるデータ・AI利活用 | 1-5. データ・AI利活用の現場 | データ・AIを活用することによって、どのような価値が生まれているかを知る | ・データサイエンスのサイクル(課題抽出と定式化、データの取得・管理・加工、 探索的データ解析、データ解析と推論、結果の共有・伝達、課題解決に向けた提案) ・流通、製造、金融、サービス、インフラ、公共、ヘルスケア等におけるデータ・AI利活用事例紹介 |
| (4)A | (4)活用に当たっての様々な留意事項(ELSI、個人情報、データ倫理、AI社会原則等)を考慮し、情報セキュリティや情報漏洩等、データを守る上での留意事項への理解をする ※モデルカリキュラム心得3-1、心得3-2が該当 | 3.
データ・AI利活用における留意事項 | 3-1. データ・AIを扱う上での留意事項 | 詳細なし | 詳細なし |
| (4)B | (4)活用に当たっての様々な留意事項(ELSI、個人情報、データ倫理、AI社会原則等)を考慮し、情報セキュリティや情報漏洩等、データを守る上での留意事項への理解をする ※モデルカリキュラム心得3-1、心得3-2が該当 | 3.
データ・AI利活用における留意事項 | 3-2. データを守る上での留意事項 | 詳細なし | 詳細なし |
| (5)A | (5)実データ・実課題(学術データ等を含む)を用いた演習など、社会での実例を題材として、「データを読む、説明する、扱う」といった数理・データサイエンス・AIの基本的な活用法に関するもの ※モデルカリキュラム基礎2-1、基礎2-2、基礎2-3が該当 | 2.
データリテラシー | 2-1. データを読む | データを適切に読み解く力を養う | ・データの種類(量的変数、質的変数) ・データの分布(ヒストグラム)と代表値(平均値、中央値、最頻値) ・代表値の性質の違い(実社会では平均値=最頻値でないことが多い) ・データのばらつき(分散、標準偏差、偏差値) ・観測データに含まれる誤差の扱い ・打ち切りや脱落を含むデータ、層別の必要なデータ ・相関と因果(相関係数、擬似相関、交絡) ・母集団と標本抽出(国勢調査、アンケート調査、全数調査、単純無作為抽出、層別抽出、多段抽出) ・クロス集計表、分割表、相関係数行列、散布図行列 ・統計情報の正しい理解(誇張表現に惑わされない) |
| (5)B | (5)実データ・実課題(学術データ等を含む)を用いた演習など、社会での実例を題材として、「データを読む、説明する、扱う」といった数理・データサイエンス・AIの基本的な活用法に関するもの ※モデルカリキュラム基礎2-1、基礎2-2、基礎2-3が該当 | 2.
データリテラシー | 2-2. データを説明する | データを適切に説明する力を養う | ・データ表現(棒グラフ、折線グラフ、散布図、ヒートマップ) ・データの図表表現(チャート化) ・データの比較(条件をそろえた比較、処理の前後での比較、A/Bテスト) ・不適切なグラフ表現(チャートジャンク、不必要な視覚的要素) ・優れた可視化事例の紹介(可視化することによって新たな気づきがあった事例など) |
| (5)C | (5)実データ・実課題(学術データ等を含む)を用いた演習など、社会での実例を題材として、「データを読む、説明する、扱う」といった数理・データサイエンス・AIの基本的な活用法に関するもの ※モデルカリキュラム基礎2-1、基礎2-2、基礎2-3が該当 | 2.
データリテラシー | 2-3. データを扱う | データを扱うための力を養う | ・データの集計(和、平均) ・データの並び替え、ランキング ・データ解析ツール(スプレッドシート) ・表形式のデータ(csv) |